基于魔乐社区openMind实现大模型微调指南(二)大模型微调实操
前言
xxxxxxxxxx在我们上一节的内容中,我们全面梳理了“大模型微调”的基础知识体系。从大模型的技术演进、Transformer架构的原理、预训练与微调范式的转变,到全参数微调与参数高效微调(PEFT)方法的发展脉络,相信你已经建立起了对大模型微调机制的整体认知框架。我们不再仅仅停留在“预训练模型能做什么”的好奇阶段,而是逐步掌握了“如何让大模型为我所用”的主动权。你已经理解:微调,不是重造一个轮子,而是在一个通用强大的引擎上,加装属于你的“专属功能模块”,让模型更懂你的业务、更贴近你的数据场景。
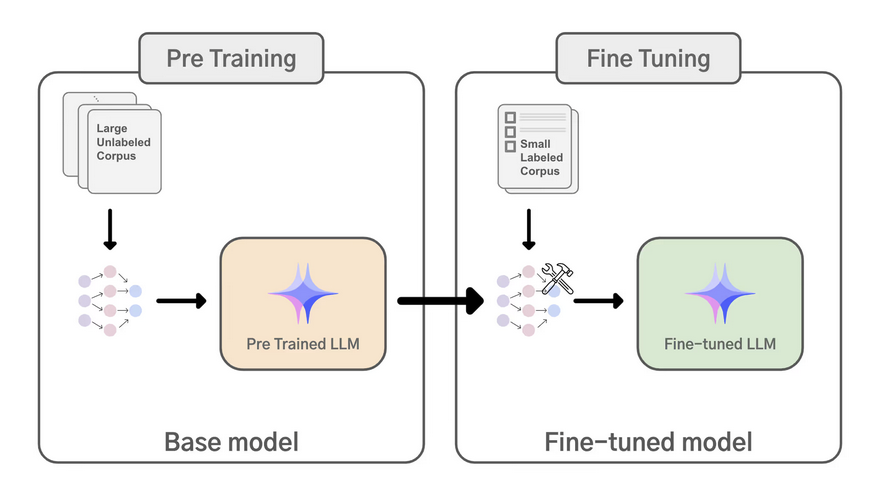
xxxxxxxxxx那么接下来的问题就是——理论到此为止了吗?当然不!本节《大模型微调实操》将是整个系列内容真正迈向实践落地的起点。我们将借助魔乐社区 openMind 工具链,从数据准备、模型选择、微调配置,到启动训练、评估效果,全流程拆解一次完整的微调工程实践。你将亲自看到那些抽象的概念,在代码和操作中一步步变成现实。无论你是初入门的AI探索者,还是希望将大模型真正落地业务场景的工程师,这一讲都将是你“动手能力”起飞的重要一站。
一、大模型微调上手指南
大模型(LLM)的预训练和微调是打造AI应用的两个关键阶段。对于人工智能初学者和对大模型感兴趣的大学生来说,理解如何使用Qwen2.5-7B-Instruct模型进行任务微调非常有价值。本文将通过一个通俗易懂的实战教程,手把手介绍从概念到代码的完整流程,涵盖文本分类、问答、摘要生成和对话生成等任务。文章包括预训练与微调的区别、微调前需要掌握的基础知识、微调的步骤详解、代码示例以及相关资源推荐。
1.1 预训练 vs 微调:有什么区别?
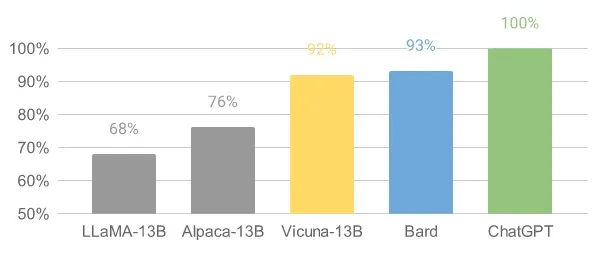
Alpaca 和 Vicuna 是 LLaMA 模型的微调版本,能够进行对话并遵循指示。根据他们的网站,Vicuna 的输出质量(根据 GPT-4 判断...)约为 ChatGPT 的 90%,使其成为您可以在本地运行的最佳语言模型。这意味着通过微调模型,您可以获得针对特定任务的更好基础模型版本。
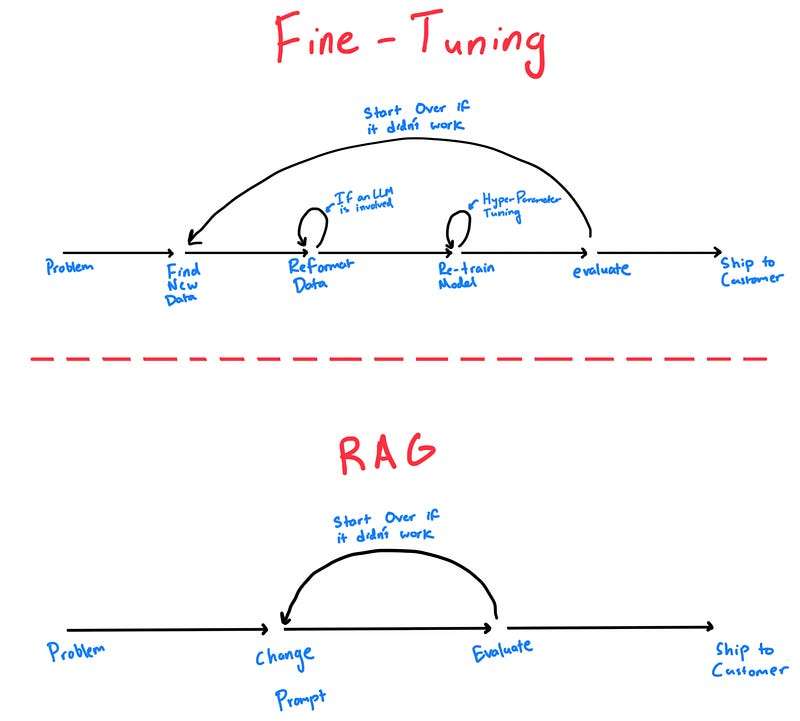
在开始实战之前,我们先明确预训练和微调这两个概念:
预训练(Pre-training):指在海量无标注文本数据上训练一个“大型语言模型”(如GPT、Qwen等)。模型通过阅读互联网语料、书籍等学会语言的统计规律和基本知识。这阶段不针对特定任务,产出的是基础模型(Base Model),例如Qwen2.5-7B就是一个7B参数的基础模型。基础模型具有通用的文本生成和理解能力,但未针对任何特定任务优化。通常基础模型不能直接胜任专业领域的问答或特定格式的输出,需要进一步打磨。
微调(Fine-tuning):指在预训练得到的大模型基础上,用特定任务或领域的标注数据进行再训练,使模型适应特定应用。微调的过程会调整模型的部分或全部参数,让模型在例如医学问答、法律咨询、客服对话等特定任务上表现更好。举例来说,Qwen2.5-7B-Instruct就是在基础模型上做了指令微调(Instruction Tuning)的版本,专门针对遵循指令、对话式输出进行了优化,因而在执行摘要、翻译、问答等指令时表现更准确、一致。简单来说,预训练是“大量阅读,学习通用知识”,而微调是“针对性训练,解决具体问题”。
为什么需要微调? 通用大模型很强大,但不可能直接解决所有垂直领域的问题。例如,一个在海量通用文本上预训练的模型可能没有掌握医学领域的专业术语或格式。如果我们希望模型帮忙生成医学报告,就需要用医疗领域的数据来微调它,让模型习得该领域的专业知识和表达方式。通过微调,我们可以让模型的任务特定性能提升,更好地适应目标领域的术语和语义。同时微调还能缓解数据稀缺性问题,在有限的标注数据下显著提升模型在特定任务上的表现。
预训练造就了模型的“大脑”和基本能力,微调则相当于请模型的“私人导师”进行强化训练,使其在特定任务上达到专家水平。接下来,我们将进入微调实战前的准备工作。
1.2 微调准备:模型、参数与数据
在动手微调Qwen2.5-7B-Instruct之前,需要了解和准备以下基础知识和要素:
1.2.1 模型参数规模与硬件要求
Qwen2.5-7B-Instruct是一个具有约7B参数的因果语言模型(Causal LM),结构包含28层Transformer、RMSNorm等机制,支持最长128K的上下文长度。7B参数模型属于较大的模型,其显存占用需要重点考虑。一般经验是16位精度加载模型需要约2倍于参数量的显存空间,7B模型大约需要14GB显存才能完整加载。。因此,在GPU上微调7B模型通常至少需要一张高端显卡(如24GB显存的RTX 3090/4090等),或者采用更高效的加载方式(例如bfloat16、8bit/4bit量化)来降低显存占用。如果有多块GPU,可以考虑使用数据并行或模型并行来分担内存压力。
操作系统与依赖: 推荐使用Linux或类似的64位操作系统环境。安装最新版的 Python 3.8+ 和 PyTorch**深度学习框架**(建议PyTorch 2.x,已支持GPU)。然后,通过pip或conda安装Hugging Face的Transformers库和相关工具:
xxxxxxxxxxpip install transformers peft datasets bitsandbytes acceleratetransformers是Hugging Face提供的模型加载和训练库。peft(Parameter-Efficient Fine-Tuning) 提供了LoRA、P-Tuning等微调方法的实现。datasets方便加载和处理训练数据(可选,如果您使用Hugging Face Datasets)。bitsandbytes用于8-bit/4-bit量化支持,如果您计划使用QLoRA或8-bit加载模型。accelerate则有助于分布式训练和混合精度训练(单卡情况下不是必需,但安装无妨)。
确保Transformers版本兼容: Qwen2.5模型已经整合进Transformers库(需版本≥4.37.0)。使用足够新的Transformers可以直接加载Qwen模型而不需要trust_remote_code=True(旧版可能需要这个参数)。如果遇到Tokenizer class QWenTokenizer does not exist之类的错误,可尝试升级或降低相关库版本。
下载模型权重: 可以通过Hugging Face Hub获取Qwen2.5模型。例如,我们以7B的指令微调版模型为基准:
xxxxxxxxxxfrom transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "Qwen/Qwen2.5-7B-Instruct"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto")第一次运行时,上述代码将自动从互联网下载模型权重并缓存(需确保网络畅通)。device_map="auto" 会将模型自动加载到GPU(若有多个GPU可平摊内存)。这里我们让torch_dtype="auto"自动选择精度(一般会是FP16/BF16),以减少显存占用。下载7B模型需要占用约十几GB磁盘空间,请提前确保空间充足。
以上是通过Hugging Face Hub获取,实操我们将通过openMind Library获取更为简单快速。
注:
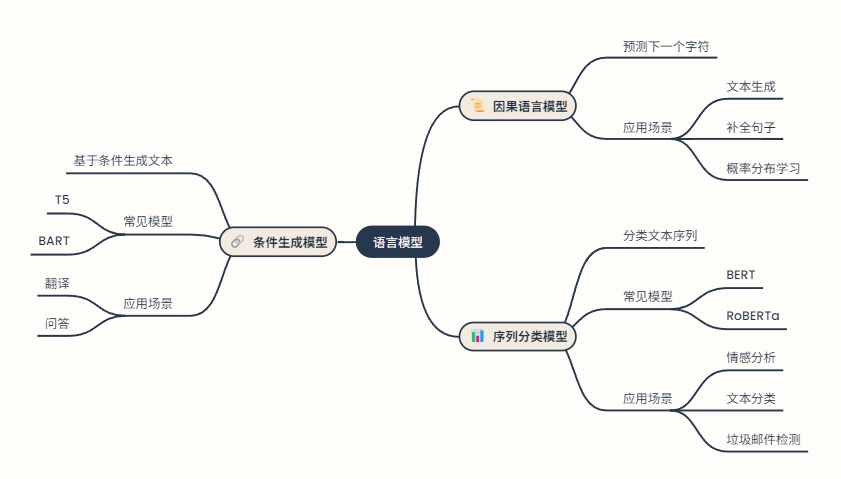
因果语言模型(Causal Language Model): 预测给定文本序列中的下一个字符,一般用于文本生成、补全句子等,模型学习给定文本序列的概率分布,并预测下一个最可能的词或字符。
条件生成模型(Conditional Generation): 基于给定的条件或输入生成新的文本,模型不仅学习文本序列的概率分布,还学习如何根据给定的条件生成文本。常见的模型包括T5(Text-to-Text Transfer Transformer)和BART(Bidirectional and Auto-Regressive Transformer)。一般用于翻译、问答。
序列分类模型(Sequence Classification): 将输入的文本序列分类到预定义的类别中。常见的模型包括BERT(Bidirectional Encoder Representations from Transformers)和RoBERTa(Robustly Optimized BERT Pretraining Approach)。一般任务为情感分析、文本分类、垃圾邮件检测。
1.2.2 微调方式与高效训练技巧
大模型的微调有多种方法,除了传统的全参数微调(SFT,全模型的有监督微调)外,还有一些参数高效微调(PEFT)技术可以大幅降低显存和算力需求。常见的方法包括 LoRA、QLoRA、Adapter、Prefix-Tuning 等。
LoRA(Low-Rank Adaptation)微调: LoRA方法会冻结预训练模型的绝大部分参数,仅在模型中引入少量可训练的低秩矩阵(通常插入到权重矩阵的旁路),使得需要更新的参数大幅减少。这样不仅避免了灾难性遗忘(不破坏原有知识),还降低了显存开销,即使在单张GPU上也能微调大模型。实践证明,LoRA微调后的效果通常接近全参数微调,但资源消耗要小得多。
QLoRA(量化 LoRA)微调: QLoRA是在LoRA基础上的进一步优化,即先将模型权重低比特量化(如4比特), 然后再应用LoRA。例如将Qwen2.5-7B模型权重量化为4-bit,可以将显存占用进一步降低约4倍。QLoRA能让我们在消费级显卡上微调几十亿参数模型成为可能。当然,极端的量化可能略有精度损失,需要在效率和效果之间权衡。
DeepSpeed 等分布式训练: DeepSpeed是微软开源的深度学习优化库,通过ZeRO并行等技术将模型参数拆分到多块GPU,有效减少单卡显存占用并提升训练效率。如果有多GPU环境或需要微调更大的模型(如几十亿参数以上),可以借助DeepSpeed的Zero Stage 2/3优化、CPU Offloading等特性来高效并行训练。同时,DeepSpeed还提供了诸如梯度检查点、显存优化等功能,使百亿级模型的微调成为可能。
综上,在微调前需要决定采用何种方式:直接全参微调(简单但耗资大),还是采用LoRA/QLoRA等高效微调(推荐给资源有限的开发者)。本教程选择使用LoRA进行微调演示,因为它对新手来说实现简单、所需资源少,但又能达到不错的效果。
1.2.3 重要超参数设置
如果把调用大模型比作烹饪,那么参数调优就是掌控火候的关键——火候太小,菜肴寡淡无味;火候太大,食材可能烧焦。同样地,在使用OpenAI API时,参数的细微调整会直接影响生成内容的精准性、创造性和实用性。无论是让AI生成一段严谨的法律条文,还是创作一首天马行空的诗歌,参数的设定都决定了输出结果的“风味”。
为了更直观地理解参数调优的重要性,我们来看几个实际案例:
案例一:智能客服中的参数调优 在智能客服场景中,用户通常希望获得准确、简洁的回答。此时,可以设置较低的 temperature(如 0.2)和 top_p(如 0.5),以减少生成内容的随机性和多样性,确保回答的准确性和一致性。 此外,可以设置适当的 max_tokens(如 100),限制回答的长度,避免冗长的回复。
案例二:内容创作中的参数调优 在内容创作场景中,如生成广告文案或社交媒体内容,通常需要富有创意和多样性的输出。此时,可以设置较高的 temperature(如 0.8)和 top_p(如 0.9),以增加生成内容的随机性和多样性,激发模型的创造力。 同时,可以适当调整 frequency_penalty 和 presence_penalty,鼓励模型使用更多新颖的表达方式,避免重复使用相同的词汇和句式。
案例三:数据分析中的参数调优在数据分析场景中,如从大量文本中提取关键信息并生成报告,通常需要结构化和准确的输出。此时,可以设置较低的 temperature(如 0.3)和 top_p(如 0.6),以减少生成内容的随机性,确保输出的准确性和一致性。 此外,可以设置适当的 max_tokens(如 200),限制输出的长度,确保报告的简洁性和可读性。
通过调整参数,如 temperature、top_p、frequency_penalty 等,可以控制生成内容的随机性、创造性和重复性,从而满足不同场景的需求。如果参数不当,则会极大影响模型输出质量:
以下是一个使用 openai.ChatCompletion.create() 方法进行对话生成的示例:
xxxxxxxxxximport openaiopenai.api_key = "your-api-key"
response = openai.ChatCompletion.create( model="qwen-max-latest", messages=[ {"role": "system", "content": "你是一个乐于助人的助手。"}, {"role": "user", "content": "请告诉我今天的天气。"} ], temperature=0.7, max_tokens=100)
print(response.choices[0].message["content"])
在上述代码中:
model指定使用的模型,如 qwen-max-latest`。messages是对话的上下文,包括系统、用户和助手的消息。temperature控制生成内容的随机性,值越高,生成的内容越多样化。max_tokens限制生成内容的最大长度。
通过上述配置,开发者可以快速集成大模型能力,为应用程序添加智能对话功能。此节个人认为是重要章节,因此在本节中,我们将深入解析 OpenAI 官方提供的 Python SDK 的五大核心接口——ChatCompletion(多轮对话)、Completion(单轮文本补全)、Embedding(文本向量化)、Audio(语音识别与翻译)和 Image(图像生成与编辑)。我们将介绍每个接口的用途、主要参数(默认值及建议范围)、参数如何影响模型输出效果与使用成本,并提供对应的 Python 示例代码。此外,每节还结合实际业务场景举例,帮助理解参数设置的效果,并在最后给出实战建议。
主要参数: 调用 openai.ChatCompletion.create() 时,常用的主要参数包括:
model(模型): 使用的模型名称。例如常用的对话模型有
"gpt-3.5-turbo"或"gpt-4"等。GPT-4 通常在处理复杂任务上效果更好,但成本更高,而 GPT-3.5-Turbo 速度快、价格低。messages(消息列表): 多轮对话消息组成的数组。每个消息是一个字典,包含
role(角色)和content(内容)。典型角色有:"system":系统角色消息,可用于设定对话的背景或规则,比如指示 AI 扮演某种身份。"user":用户消息,即用户提出的问题或输入。"assistant":助手(AI)消息,即此前模型产生的回答。 开始对话时通常提供一个 system 指令和用户提问,模型会根据这些生成 assistant 回复。随着对话进行,messages 列表会不断加入新的 user 和 assistant 消息,以维持上下文。max_tokens(最大生成长度): 控制模型输出的最长 Token 数。默认情况下,如果不设置,模型会尽可能长地生成直到达到模型上下文上限或遇到停止信号。设置此参数可以防止输出过长(从而控制成本),但若设得过小可能导致回答不完整。一般根据需求设置几十到上千不等。例如希望简短回答可设定如
max_tokens=100。temperature(温度): 控制生成文本的随机性,取值范围 0~2,默认值为 1。温度越高,回复越随机、富有创造力;温度越低,回复越稳健严谨、更加确定。比如
temperature=0时,每次回答几乎相同,适合问答、代码等需要确定性的场景;temperature=0.7时,回复会更丰富多样,适合创意写作等需要一定随机性的场景。top_p(概率截断): 又称 核采样,取值 0~1,默认值为 1。它控制模型考虑预测下一个词时累积概率的范围。当
top_p<1时,模型仅从概率前top_p部分的词中采样,例如top_p=0.1意味着只考虑前10%概率质量的词。通常和 temperature 二选一调整,不需要同时修改这两个参数。在需要输出更符合常理语句时,可降低 top_p 来减少罕见词输出的可能性。n(返回结果数量): 一次请求生成多少个回复,默认 1。如果设置
n>1,接口会返回多个备选回复。适用于希望从多种应答中进行选择的场景,比如生成多种文案创意。但要注意n值越大,消耗的 Token 和费用近似线性增加(相当于做了多次生成)。stream(流式输出): 是否启用流式输出,默认
False。若设为True,API 将逐步返回部分消息(类似打字机效果),适合实时应用。例如在聊天界面一点点显示回答。流模式下需在代码中迭代读取流响应。需要注意的是,开启流式并不改变最终内容或费用,但可以降低延迟、提升用户体验。stop(停止标志): 可以是字符串或字符串列表,表示生成过程中遇到该标志时就停止输出,不再继续生成。例如设置
stop=["\n\nHuman:"]可以在对话模型开始生成下一个 Human/user 提示时强制停止。合理使用 stop 有助于避免模型跑题或输出多余内容。默认情况下没有强制停止标志,模型会根据自身学习到的停止符(如系统消息或 max_tokens 耗尽)来结束。presence_penalty(话题新颖度惩罚): 数值范围 -2.0~2.0,默认 0。。正值会惩罚模型重复提及对话中已出现过的主题,提高引入新话题的倾向。换句话说,值越高,模型越倾向于不重复自己,鼓励拓展到新内容;负值则反之,会提高模型重复提及已有内容的概率。
frequency_penalty(频率惩罚): 数值范围 -2.0~2.0,默认 0。正值会惩罚模型重复输出相同字词的频率。值越高,输出越不容易重复用词,以避免内容重复啰嗦;负值则可能使模型更倾向重复字词。比如在总结场景下可设置略高的频率惩罚以避免模型重复句子。在押韵诗歌等场景或需重复关键词时则可使用负值降低惩罚。
functions(列表,可选):函数调用功能的描述列表。每个函数由 name、description、parameters 等定义,用于引导模型以函数格式输出。这是 ChatCompletion 新增的高级特性,可让模型按照指定函数的参数格式返回结构化数据。当提供此参数时,模型可能选择返回一个函数调用结果而非自然语言。
function_call(字符串或字典,可选):指定函数调用方式。默认为
"auto"让模型自行决定是否调用函数;可设为"none"强制禁止函数调用;或指定为某个函数名强制模型调用该函数。配合 functions 参数使用,用于更精细地控制模型输出格式(比如强制模型给出JSON调用某函数的参数)。user(字符串,可选):用于标识终端用户的唯一标识符。这个信息不会影响生成内容,但会在日志中记录,OpenAI 用它来监控滥用。对于多用户的应用,传递 user 参数有助于将请求与用户对应,以满足审计或安全需求。
参数对内容和成本的影响: ChatCompletion 接口的输出很大程度上由 prompt消息内容 和 模型 决定,但上述参数提供了重要的调优手段:
创意与一致性:
temperature和top_p直接决定回复的随机性。较低的 temperature(接近0)让模型每次都选取最可能的词,输出偏确定和可预测,这适合事实问答或代码生成等需要稳定结果的任务;较高的 temperature/top_p 允许模型探索不太可能的词,增加回复的多样性,用于创意写作、对话聊天等场景会更生动。但是温度过高(如 >1.5)可能导致胡言乱语或跑题,需要谨慎调整。输出长度:
max_tokens决定回复长度上限。如果希望简洁回答,可设一个较小的 max_tokens;生成长文则应提高该值。但无论何种情况,max_tokens 越大潜在成本越高,因为模型可能输出更多内容。同时由于每个 token 都按单价计费(输入和输出均计费),限制 max_tokens 也是控制花费的方法之一。对于聊天模型,例如 GPT-3.5,每千 tokens 定价几美分左右,所以生成100 tokens和1000 tokens在成本上相差一数量级。重复与话题控制:
presence_penalty和frequency_penalty提供对内容重复度和话题广度的控制。举例来说,在一个产品描述生成任务中,如果模型倾向重复某些词,可以增加 frequency_penalty,使其换用不同表达。而在头脑风暴应用里,提高 presence_penalty 可以促使模型不断引入新创意而不是反复纠结旧点子。反过来,如果希望模型紧扣用户给定的话题,可以设置适度的负值以鼓励模型重复提及相关主题词。不过一般大多数应用保持默认0即可,除非有明确需要。多回复与成本: 使用
n>1可以一次性得到多种不同风格或角度的回答,例如在客服聊天中生成多个答复备选。但需要注意每个候选实际上是独立调用模型生成,费用也近似按倍数增加。例如生成3个回复的费用约是单回复的3倍(因为输出 token 数增加)。因此除非有挑选最佳回答的需求,否则不建议轻易将 n 调太高。函数输出: 提供
functions参数会影响模型输出——模型可能返回一个函数调用而非直接回答。这对工具使用场景很有用,例如要求模型返回结构化数据给程序处理。如果不想模型走函数调用分支,应避免提供 functions 或将 function_call 设为 "none"。流式输出:
stream=True虽然不改变最终内容,但对交互体验影响显著。在需要实时显示的应用(如聊天机器人打字效果)中使用流式能降低延迟,提高用户感知速度。不过实现上要处理好分片消息的组装。另外,开启 stream 并不会减少费用,因为总Token用量不变,但由于可边生成边发送,在长内容时可以节省一点总体请求时间。
下面我们以 qwen-long 模型为例,演示 ChatCompletion 接口的基本用法。
xxxxxxxxxx# 准备对话消息messages = [ {"role": "system", "content": "你是一位乐于助人的数学讲师,用通俗易懂的语言回答问题。"}, {"role": "user", "content": "请解释一下 Monty Hall 问题 的意义。"}]
# 不同参数设置下调用 ChatCompletion 接口response_default = client.chat.completions.create( model="qwen-max-latest", messages=messages)print("默认参数回复:\n", response_default.choices[0].message.content)
response_creative = client.chat.completions.create( model="qwen-max-latest", messages=messages, temperature=1.2, # 提高随机性 n=2, # 获取2个不同风格的回答 max_tokens=150 # 扩大量以获得详细解释)for i, choice in enumerate(response_creative.choices): print(f"\n回复 {i+1}:\n{choice.message.content}")在上述代码中,response_default 使用默认参数,会得到模型较为中规中矩的解释。而 response_creative 则提高了温度并让模型输出两个版本,可能一个解释更风趣类比,另一个更严谨数学。需要强调的是,n=2 虽然让我们一次获得两个答案,但其消耗的 Token 也是双倍的(输入部分共享但输出两份)。实际应用时,可以根据需求权衡这种一次多回复的策略。
应用场景与参数调优: 在聊天机器人或对话系统中,合适地调整这些参数能够显著改善用户体验。例如,当构建一个代码助理时,为了保证代码输出的确定性和正确性,常将 temperature 设为 0,使模型每次都产生几乎相同的结果,减少随机 bug。同时可能设置较高的 max_tokens 以便生成较长的代码段,并利用 stop 参数让模型在输出完函数定义后停止,避免啰嗦解释。
又如,在创意写作场景(故事生成、诗歌创作),可以将 temperature 提高到 1.0 以上甚至 1.5,并将 presence_penalty 适当提高以鼓励引入新主题、新意象,从而获得更有想象力的输出。然而要注意此时可能需要对结果进行人工筛选,因为高随机性下质量波动也会增大,必要时可以请求多次或增加 n 来获取多个候选文本。
1.2.4 微调数据格式
数据集是微调的燃料。不同任务的数据需要整理成模型可理解的输入-输出对格式。由于Qwen2.5-7B-Instruct是指令微调模型,我们采用“指令 + 输入 -> 模型输出”的格式来组织训练数据。例如:
文本分类任务: 可以将每条数据表示为一个指令和待分类文本,让模型输出分类标签。例如情感分类的数据格式可以这样组织:
xxxxxxxxxx{ "instruction": "判定以下句子的情感倾向(正面或负面):", "input": "这家餐厅的服务真棒,菜品也非常美味!", "output": "正面"}
上例中,instruction提供了模型需要执行的任务说明,input是需要分类的文本,output是期望模型给出的标签。微调时模型会学习在类似指令下输出正确的情感极性。
问答(QA)任务: 如果是知识问答或阅读理解,可以让instruction说明要求,input中提供问题和相关上下文,output给出回答。例如:
xxxxxxxxxx{ "instruction": "阅读以下背景段落,并回答所提问题:", "input": "背景:世界上最高的山峰是哪一座?\n问题:世界上最高的山峰是?", "output": "世界上最高的山峰是珠穆朗玛峰。"}
模型将学习根据提供的背景信息,提取并输出正确答案。
摘要生成任务: 格式类似,将待摘要的文本放入input,指令要求模型生成摘要,output为参考摘要。例如:
xxxxxxxxxx{ "instruction": "请对以下新闻稿件生成摘要:", "input": "全文:据新华社报道,近日…(此处省略原文)…", "output": "这篇新闻报道了近期发生的…(此处是摘要)…"}
这样模型学习如何压缩文本并提取关键信息进行总结。
对话生成任务: 对话数据通常是多轮的,格式略有不同。一种方式是将多轮对话扁平化为一段特殊格式的文本。例如可以用角色标签来组织:
xxxxxxxxxx{ "instruction": "以下是一段用户与AI助手的对话,请根据对话内容给出AI助手最后的回复。", "input": "用户:你好,帮我预定一下今晚去纽约的机票。\n助手:好的,请问出发城市是哪里?\n用户:出发城市是旧金山。", "output": "好的,我正在为您查询从旧金山到纽约的航班,请稍等。"}
上例中,input包含多轮交互,以\n换行区分说话者。模型需根据对话上下文,在instruction要求下生成助手的新回复。实际训练对话模型时,也可以采用更复杂的格式(如OpenAI的role: user/assistant JSON格式)。
Qwen2.5-7B-Instruct支持多轮对话,在推理时通常需要提供类似ChatGPT的messages结构。
我们需要收集或构建针对目标任务的高质量训练数据。数据量不用像预训练那样动辄上亿条,但应覆盖多样的情况并确保正确性。准备好的数据划分为训练集、验证集(和测试集),例如按8:1:1拆分,这样可以在训练过程中用验证集评估模型性能并调参。确保数据格式和指令与模型预期格式一致,才能充分发挥指令微调模型的优势。
主流大模型微调数据集一览
| 数据集名称 | 领域/特点 | 适用任务 | 下载地址 |
|---|---|---|---|
| IEPile | 中英双语信息抽取,覆盖医学、金融等领域,含高质量标注指令数据。 | 信息抽取、跨领域微调 | https://huggingface.co/datasets/zjunlp/iepile |
| ShareGPT 90k | 中英文双语人机问答数据,覆盖复杂真实场景。 | 对话模型训练、跨语言生成 | https://huggingface.co/datasets/FreedomIntelligence/ShareGPT-CN |
| PAWS-X | 跨语言释义识别对抗数据集,支持6种语言(含中文)。 | 多语言文本匹配、语义相似度 | https://huggingface.co/datasets/google-research-datasets/paws-x |
| Wikipedia-QA | 56种语言的维基百科文章,经清理后适用于预训练与知识增强。 | 预训练、知识库构建 | https://huggingface.co/datasets/fibonacciai/Persian-Wikipedia-QA |
| Chinese-Poetry | 包含5.5万首唐诗、26万首宋词等古典文集,适合古文生成任务。 | 古典文本生成、文化领域微调 | https://huggingface.co/datasets/Iess/chinese_modern_poetry |
| MCFEND | 多源中文假新闻检测数据集,支持虚假信息识别。 | 假新闻检测、内容安全 | https://my5353.com/30429 |
| Ape210K | 21万道小学数学题,含答案与解题步骤,适配数学推理任务。 | 数学问题生成、逻辑推理微调 | https://huggingface.co/datasets/MU-NLPC/Calc-ape210k |
| Alpaca | 由斯坦福大学创建,通过微调模型生成,包含约 5.2 万个指令跟随数据样本。 | 如常识问答、文本生成等 | https://huggingface.co/datasets/shibing624/alpaca-zh |
| fortune-telling | 占卜数据集 | 风水占卜相关的数据集 | https://huggingface.co/datasets/Conard/fortune-telling |
| rm-static | 强化学习典型开源数据集 | 人类偏好排序数据集,用于强化学习微调、训练奖励模型。 | https://huggingface.co/datasets/Dahoas/rm-static |
| NuminaMath-CoT | 思维链数据集 | 约 86 万道中国高中数学练习题、以及美国和国际数学奥林匹克竞赛的题目,每个问题的解答都采用了思维链(CoT)的格式。 | https://huggingface.co/datasets/AI-MO/NuminaMath-CoT |
| Chinese-DeepSeek-R1-Distill-data-110k | 中文基于满血 DeepSeek-R1 蒸馏数据集。 | 数据集中不仅包含 math 数据,还包括大量的通用类型数据,总数量为 110K | https://huggingface.co/datasets/Congliu/Chinese-DeepSeek-R1-Distill-data-110k |
| the_cauldron | 多模态微调典型开源数据集 | 包含 50 个大规模视觉语言训练数据集(仅训练集),用于多任务视觉语言模型的微调。数据集结构包含 images(图片列表)和texts(对话文本),其中对话以用户提问、模型回答的形式呈现,覆盖问答、选择等任务(如TQA数据集示例)。 | https://huggingface.co/datasets/Conard/fortune-telling |
| PubMedQA | 医学领域典型开源数据集。 | 基于 PubMed 文献的医学问答数据集,包含医学研究相关问题,适合医疗信息抽取与领域适配任务。 | https://huggingface.co/datasets/qiaojin/PubMedQA |
| imdb | 文本分类、情感分析典型开源数据集 | 大型电影评论数据集,包含用户评论到电影评分的映射关系,适用于对评论进行积极、负面分类的微调任务。 | https://huggingface.co/datasets/Conard/fortune-telling |
| CAMEL | 多轮对话数据集 | 包含约 22.9 万条结构化的多轮对话数据。 | https://huggingface.co/datasets/camel-ai/ai_society |
1.3 openMind Library基础
在上一次直播中我们已经在体验空间中通过建立Application应用,已经可以使用Jupyternotebook了,因此openMind Library将在体验空间中,通过代码运行实时获取效果来进一步帮助我们理解和学习。正所谓“工欲善其事,必先利其器”,我们需要对openMind Library先有初步了解,再来实操会更有效率。
1.3.1openMind Library概述
openMind Library是一个深度学习开发套件,通过简单易用的API支持模型预训练、微调、推理等流程。该开发套件通过一套接口兼容PyTorch和MindSpore等主流框架,并且仅支持昇腾NPU处理器。因此我们创建体验空间的算力资源一定要选择NPU算力资源:

为了应对大模型分布式训练的挑战,openMind Library提供了预训练接口,支持MindSpeed、Accelerate等加速库,帮助开发者顺畅快速地训练大模型。由于训练大模型算力需求庞大而且毕竟复杂,我们主题是微调大模型,因此关于模型训练的openMind Library我们不作过多了解。
openMind Library基于transformers库,集成了PyTorch框架下主流第三方工具的功能,提供了一键式的封装的微调命令行接口解决方案,涵盖了从数据处理、权重加载,到低参数微调、量化适配,以及微调和训练跟踪的全流程功能。因此关于openMind Library的微调问题我们是可以参考PyTorch如何对大模型做微调的。同时,openMind Library还提供了昇腾NPU亲和算子优化等加速手段,显著提升模型训练效率。
而且微调之前我们需要下载加载大模型,微调过后还需要推理测试微调效果,这方面openMind Library对Transformers和MindFormers的AutoClass、Pipeline、Trainer等接口进行封装,并增强了其功能,提供了对应的SDK。还提供了从魔乐社区自动下载和加载模型的能力,同时扩展新增了昇腾NPU亲和的特性,有效提升在昇腾NPU上进行模型训练推理的性能
openMind Library还可以和PEFT、DeepSpeed、bitsandbytes等三方库配合使用,也就是我之前给大家展示的微调算法代码,在创建的体验空间中,里面有使用openMind Library进行模型开发的实践文档,包含openMind和LLaMA Factory配合进行模型微调等案例。
二、openMind Library上手
由于仅支持昇腾NPU处理器,若本地没有部署NPU环境,可以在社区新建体验空间及部署Application体验空间,在Application体验空间的“Notebook APP”上使用NPU环境。Notebook已支持单卡的NPU算力资源基础环境,用户可直接进行以下操作。
如果想在自己的电脑上面部署openMind Library,需要确保你是NPU,以Python 3.8版本为例:
基于PyTorch快速安装openMind Library
xxxxxxxxxxconda create -n your_venv_name python=3.8conda activate your_venv_name
# 基于PyTorch和NPU安装openMind Librarypip install openmind[pt]基于MindSpore快速安装openMind Library
xxxxxxxxxxconda create -n your_venv_name python=3.8conda activate your_venv_name
# 基于MindSpore和NPU安装openMind Librarypip install openmind[ms]openMind Library原生兼容PyTorch和MindSpore等主流框架,方便用户使用。openMind Library在同一时刻仅支持在一种框架上运行。如果同时安装多种框架,openMind Library将抛出错误。
2.1数据加载
目前openMind Library集成适配了datasets,可用于加载魔乐社区上的数据集。openmind.omdatasets.OmDataset类基于datasets抽取了下载相关代码,依托于patch的方式适配了openmind_hub,支持从魔乐社区下载数据集。采用OmDataset.load_dataset('repo_name/dataset_name')的方式可以下载数据集,返回特定的datasets.dataset_dict.DatasetDict类。
目前该类仅支持在PyTorch框架下使用,暂不支持MindSpore框架。
数据集下载
OmDataset.load_dataset()方法目前支持下载的数据集格式如下:
parquet
json或者jsonl
tar.gz
csv
下载python脚本加载魔乐社区数据集
下载python脚本加载三方站点数据集
具体示例如下。
openmind已暴露Omdataset接口,可直接从openmind中导入。
xxxxxxxxxxfrom openmind import OmDataset如果有其他开发需求,也可基于相对路径导入。
xxxxxxxxxxfrom openmind.omdatasets import OmDatasetOmDataset支持下载parquet格式数据集,以下为用例:
xxxxxxxxxxdata = OmDataset.load_dataset("modeltesting/test_parquet")print(data)
'''DatasetDict({ test: Dataset({ features: ['input', 'output'], num_rows: 2 })})'''
print(data['test']['input'])
'''['input_label1', 'input2_label1']'''
下载json或jsonl格式数据集
OmDataset下载数据集支持json或jsonl格式,以下为用例:
xxxxxxxxxxdata = OmDataset.load_dataset("modeltesting/test_json")print(data)
'''DatasetDict({ test: Dataset({ features: ['input', 'output', 'instruction'], num_rows: 2 })})'''
print(data['test']['instruction'])
'''['Create an array of length 2 which .....'''下载targ.gz格式数据集
OmDataset下载数据集支持tar.gz格式,以下为用例:
xxxxxxxxxxdata = OmDataset.load_dataset("modeltesting/test_targz")print(data)
'''DatasetDict({ test: Dataset({ features: ['__key__', '__url__', 'jsonl'], num_rows: 1 })})'''
print(data['test']['jsonl'])
'''[b'{"chosen": "\\n\\nHuman: Do you know why turkeys became the official food of thanksgiving?....'''下载csv格式数据集
OmDataset下载数据集支持csv格式,以下为用例:
xxxxxxxxxxdata = OmDataset.load_dataset("modeltesting/test_csv")print(data)
'''DatasetDict({ test: Dataset({ features: ['input', 'output'], num_rows: 2 })})'''
print(data['test']['input'])
'''['input1', 'input2']'''下载python脚本加载魔乐社区数据集
支持从魔乐社区数据集仓库下载python脚本,并根据python脚本进一步下载数据集文件,适用于对数据集进行更细化的处理操作。
python脚本需要带有魔乐社区对应文件的下载链接,以test_py_image的test.py脚本为例:
xxxxxxxxxxdef _split_generators(self, dl_manager): DL_URLS = [ f"https://modelers.cn/api/v1/file/modeltesting/test_py_image/main/media/{name}" for name in ["test.jpg"] ] archive_path = dl_manager.download_and_extract(DL_URLS) return [ datasets.SplitGenerator( name=datasets.Split.TEST, gen_kwargs={"archive_path": archive_path}, ), ]从相关代码中可见,涉及下载对应文件时,URL指定了魔乐社区文件下载接口路径,代码里https://modelers.cn/api/v1/file/modeltesting/test_py_image/main/media/XXX 指定了文件下载的接口路径,然后使用该接口路径可以自定义下载。该接口路径可以通过om_hub_url拼接获取。
xxxxxxxxxxfrom openmind_hub import om_hub_urlom_hub_url(repo_id="repo_name/datasets_name", filename="test.json")
'''https://modelers.cn/api/v1/file/repo_name/datasets_name/main/media/test.json'''可尝试下载以下用例,请注意使用python脚本下载数据集文件时需要添加参数trust_remote_code=True。
xxxxxxxxxxdata = OmDataset.load_dataset("modeltesting/test_py_image")print(data)
'''DatasetDict({ test: Dataset({ features: ['image'], num_rows: 1 })})'''
print(data['test']['image'])
'''[<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1788x688 at 0x7FCB56B6A3D0>]'''下载python脚本加载三方站点数据集
支持从魔乐社区数据集仓库下载python脚本,并根据python脚本从第三方站点进一步下载数据集相关文件:
xxxxxxxxxx_URL = "https://rajpurkar.github.io/SQuAD-explorer/dataset/"_URLS = { "train": _URL + "train-v1.1.json", "dev": _URL + "dev-v1.1.json",}
...
def _split_generators(self, dl_manager): downloaded_files = dl_manager.download_and_extract(_URLS) return [ datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"filepath": downloaded_files["train"]}), datasets.SplitGenerator(name=datasets.Split.VALIDATION, gen_kwargs={"filepath": downloaded_files["dev"]}), ]从相关代码中可见,涉及下载对应文件时,URL指定了第三方站点。可尝试以下用例进行下载,请注意使用python脚本下载数据集文件时需要添加参数trust_remote_code=True。
xxxxxxxxxxdata = OmDataset.load_dataset("modeltesting/test_py_github", trust_remote_code=True)print(data)
'''DatasetDict({ train: Dataset({ features: ['id', 'title', 'context', 'question', 'answers'], num_rows: 87599 }) validation: Dataset({ features: ['id', 'title', 'context', 'question', 'answers'], num_rows: 10570 })})'''
print(data['train']['question'][0])
'''To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?'''2.2加载模型权重
我们可以通过openMind Library来下载模型权重,openMind Library pipeline方法支持PyTorch和MindSpore两种框架。此外,pipeline方法支持多个领域的任务,例如文本生成、文本分类、图像识别等。
pipeline基本用法
当前的pipeline支持两种框架:PyTorch和MindSpore,在定义pipeline时,通过参数framework来指定,Pytorch框架为pt,MindSpore框架为ms。此外,Pytorch框架支持两种backend:transformers和diffusers,MindSpore支持三种backend:mindformers、mindone和mindnlp,通过参数backend传入。
在openMind Library中,每种框架下的各类推理任务,都有相应的pipeline方法。例如,在PyTorch框架下,文本转音频任务可以通过TextToAudioPipeline方法来实现。为了简化操作,我们提供了一个通用的pipeline方法,支持加载对应任务的方法。
我们检索到目标模型:
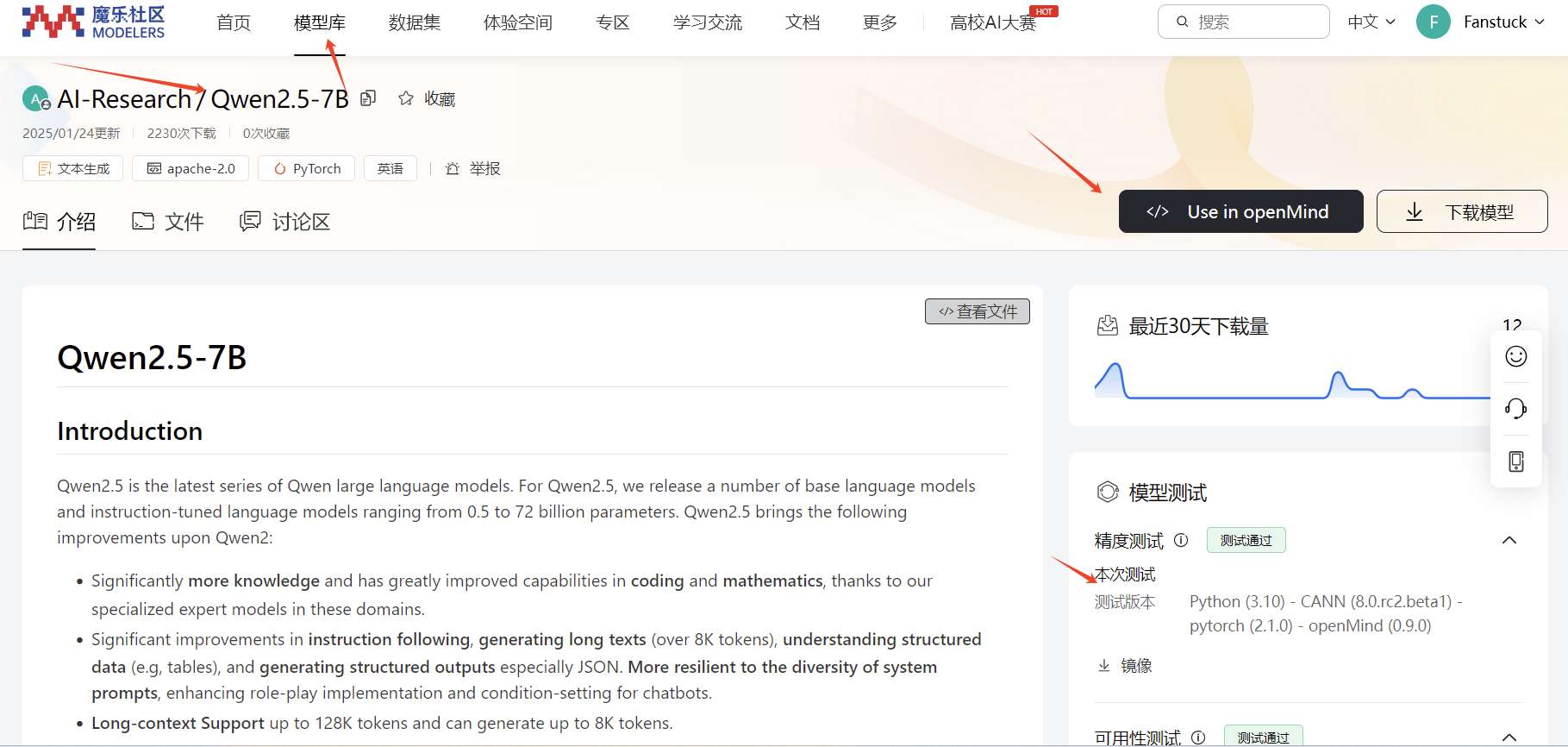
点击Use in openMind可以看到调用下载代码:
xxxxxxxxxx# Use pipelinefrom openmind import pipelinepipe = pipeline("text-generation", model="AI-Research/Qwen2.5-7B", framework="pt")pipe("Give me some advice on how to stay healthy.")可以直接在我们的Application空间上面运行:
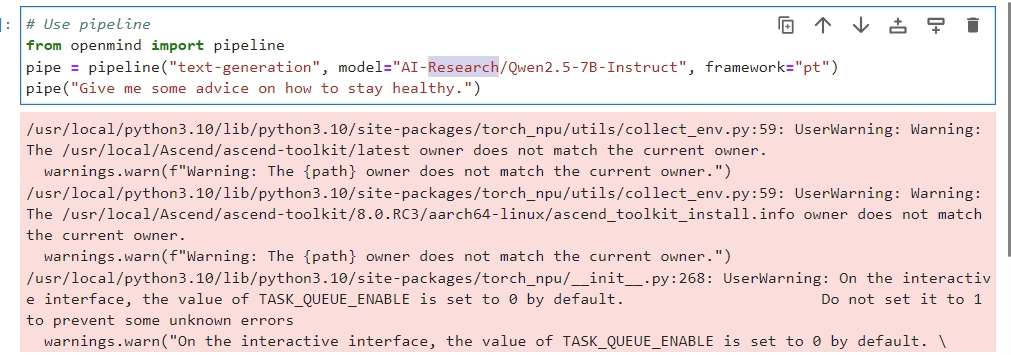
通过pipe提交prompt可获取大模型回答。

通过配置task,model,framework和backend,可以加载对应框架和任务的模型。
微调训练中需要指定模型进行下载和加载,配置参数为model_id和model_name_or_path。需要注意的是,在同一yaml脚本中,二者仅支持任选其一,不允许同时配置。
方法一:通过model_id参数可选取内置的模型,根据model_id匹配魔乐社区中的模型仓库名,便于模型的快速下载。配置方式如下:
xxxxxxxxxxmodel_id: Qwen2-7B当前内置模型可查看下表,将会持续更新:
| 模型系列 | model_id |
|---|---|
| Qwen2 | Qwen2-7B |
| Qwen2.5 | Qwen2.5-7B |
方法二:用户可通过model_name_or_path参数,指定魔乐社区模型仓库名或者本地模型路径。
当使用本地模型时,可传入模型的绝对路径:
xxxxxxxxxxmodel_name_or_path: /local/path/
可指定魔乐社区模型仓库名,如AI-Research/Qwen2-7B模型:
xxxxxxxxxxmodel_name_or_path: AI-Research/Qwen2-7B
使用model_id或model_name_or_path时,可通过cache_dir参数设置权重缓存位置:
xxxxxxxxxxcache_dir: /home/cache_model权重会被保存到/home/cache_dir路径,如果不设置则保存在默认路径。需要注意的是,当设置cache_dir路径时,用户需要同步设置HUB_WHITE_LIST_PATHS环境变量:
xxxxxxxxxxexport HUB_WHITE_LIST_PATHS=/home/cache_modelpipeline重要参数
需要注意pipeline的重要参数:
framework
pipeline支持PyTorch(pt)和MindSpore(ms)两种框架,并通过framework参数来进行指定。以下为运行在MindSpore框架上的pipeline实例:
xxxxxxxxxxfrom openmind import pipeline
text_pipeline_ms = pipeline(task="text-generation", model="MindSpore-Lab/baichuan2_7b_chat", framework='ms')output = text_pipeline_ms("hello!")
backend
PyTorch框架支持以下两种backend:transformers和diffusers。MindSpore框架支持三种backend:mindformers、mindone和mindnlp。通过backend参数来进行指定。
以下为运行在MindSpore框架,后端指定为mindnlp的pipeline实例:
xxxxxxxxxxfrom openmind import pipeline
text_pipeline_ms = pipeline(task="text-generation", model="AI-Research/Qwen2-7B", framework='ms', backend="mindnlp")output = text_pipeline_ms("Give me some advice on how to stay healthy.")
device
用户可以通过device参数来指定推理任务所在的处理器,当前支持CPU、NPU类型的处理器。如果不指定device参数,pipeline将会自动选取处理器。无论选择哪种处理器,在PyTorch框架和MindSpore框架上都可以正常运行。以下为运行在各处理器上的示例:
指定在CPU上
xxxxxxxxxxgenerator = pipeline(task="text-generation", device="cpu")指定在NPU上
xxxxxxxxxx# PyTorchgenerator = pipeline(task="text-generation", device="npu:0")model和tokenizer
model参数除了支持传入模型地址,也支持传入实例化的模型对象来进行推理,model传入实例化的模型对象时,tokenizer也必须传入特定的实例化对象:
xxxxxxxxxxfrom openmind import pipelinefrom openmind import AutoModelForSequenceClassification, AutoTokenizer
# 创建模型对象,并进行推理model = AutoModelForSequenceClassification.from_pretrained("PyTorch-NPU/distilbert_base_uncased_finetuned_sst_2_english")tokenizer = AutoTokenizer.from_pretrained("PyTorch-NPU/distilbert_base_uncased_finetuned_sst_2_english")text_classifier = pipeline(task="text-classification", model=model, tokenizer=tokenizer, framework="pt")
outputs = text_classifier("This is great !")# [{'label': 'POSITIVE', 'score': 0.9998694658279419}]
use_silicondiff
对于diffusers侧的任务,可以使用use_silicondiff参数来加速,提升推理的性能。
xxxxxxxxxxfrom openmind import pipelineimport torch
generator = pipeline(task="text-to-image", model="PyTorch-NPU/stable-diffusion-xl-base-1_0", device="npu:0", torch_dtype=torch.float16, use_silicondiff=True, )
image = generator("masterpiece, best quality, Cute dragon creature, pokemon style, night, moonlight, dim lighting")
特定参数
pipeline提供了特定参数进行模型推理,可允许单独配置,以帮助用户完成工作。例如,对于文本生成任务,可以通过指定max_new_tokens和num_beams参数来控制生成的文本长度和生成的beam大小,以影响生成的结果:
xxxxxxxxxxfrom openmind import pipeline
# 设置特定任务参数params = { "max_new_tokens": 50, # 生成的文本长度限制为50个token "num_beams": 5 # 使用beam search算法生成文本,beam大小为5}
text_generator = pipeline("text-generation", device="npu:0", trust_remote_code=True, **params)generated_text = text_generator("Once upon a time,")print(generated_text)
'''输出:Once upon a time, there was a small village nestled between two mountains. The villagers lived simple lives, working the land and taking care of their families. One day, a stranger arrived in the village. He was a wise old man with a long white beard and a ro'''
2.3模型微调
PyTorch模型微调
transformers库是PyTorch模型开发的主流套件。以此为基础结合PyTorch侧主流生态库,openMind Library为用户提供了一键式训练启动命令,帮助用户快速实现从数据处理、多站点权重加载,到低参数微调、量化适配,以及微调和训练跟踪的全流程功能。
当前支持特性如下:
微调算法:SFT
高效参数微调算法:Full,LoRA,QLoRA
加速优化:npu_fusion_attention,npu_rms_norm
训练监控:SwanLab
分布式训练:单机单卡,单机多卡,DeepSpeed
导出:LoRA权重合并
openMind Library提供命令行接口(command-line interface, CLI),支持用户在shell环境下交互式实现训练流程。用户只需要通过openmind-cli train demo.yaml命令,就可以动态解析yaml文件里的配置参数,并自动完成训练全流程。
openMind Library命令行接口内置于openMind Library中,安装openMind Library即可使用。
模型微调示例
openMind Library通过解析yaml文件的方式拉起微调训练。用户需要配置一个微调相关的yaml文件,然后通过openmind-cli train命令行方式运行,openMind Library会自动完成参数解析和微调流程配置运行。以下为一个简单可运行的示例demo.yaml。
xxxxxxxxxx# modelmodel_idQwen2-7B
# methodstagesftdo_traintruefinetuning_typefulllogging_steps1max_steps10
# datasetdatasetalpaca_zh_51k, alpaca
# trainoutput_dirsaves/Qwen2-7B/sft/lora/overwrite_output_dirtrue
运行命令为:
xxxxxxxxxxopenmind-cli train demo.yamlyaml文件内的配置包括微调算法参数,模型参数,数据集参数和训练参数。
微调算法及参数配置
用户可设置stage参数选择模型训练过程。目前仅支持sft微调。
xxxxxxxxxxstage: sft全参微调
openmind-cli train支持用户选择全参训练或者低参微调训练,目前可通过finetuning_type进行配置。全参训练可按以下配置:
xxxxxxxxxxfinetuning_type: fullLoRA微调
如果用户需要进行LoRA微调,可以参考以下内容进行配置。
在脚本中配置finetuning_type来启动LoRA微调:
xxxxxxxxxxfinetuning_type: lora如果需要调整LoRA微调配置,可以新增以下参数:
xxxxxxxxxxfinetuning_type: loralora_alpha: 16lora_dropout: 0lora_rank: 8lora_target_modules: q_proj其中lora_alpha,lora_dropout和lora_rank参数解析已提供默认值,如无必要用户可不配置。lora_dropout默认为0,lora_rank默认为8,lora_alpha默认为lora_rank * 2。
lora_target_modules参数配置存在如下选择:
如果该参数不设置,则会通过模型
config.json中的model_type自动选取合适的适配层,例如Qwen2系列模型自动识别为q_proj,k_proj。该参数设置为all,则该模型所有可适配层都会参与低参微调。
该参数设置为特定层,如
q_proj, k_proj,则会自动判别该层是否支持低参训练,如果支持则参与训练。
QLoRA微调
QLoRA微调通过量化和LoRA微调的结合,降低了计算资源需求和显存使用。openmind-cli train支持基于bitsandbytes的QLoRA微调,目前已支持NF4下的4bit量化。用户可通过load_in_4bit参数进行开启,具体使用方式如下。
步骤1 Ascend NPU下安装bitsandbytes,可参考文档bitsandbytes,也可以参考以下流程:
前置条件:安装bitsandbytes前请确保环境中已安装好cann包和torch_npu,并source /xxx/your_folder/cann/ascend-toolkit/set_env.sh,若未安装,请参照参考openMind Library安装指南安装;cmake版本不低于3.22.1,g++版本不低于12.x,若未安装,可通过如下命令安装编译环境:
xxxxxxxxxxapt-get install -y build-essential cmake # 注:此为Debian系列操作系统安装命令,openEuler、CentOS等请替换为相应的命令安装。在安装bitsandbytes之前,可通过如下示例判断安装环境是否配置完成:
xxxxxxxxxx# source /xxx/your_folder/cann/ascend-toolkit/set_env.sh # 请在终端先执行本条命令,将路径替换为实际安装路径
import torchimport torch_npu
x = torch.randn(2, 2).npu()y = torch.randn(2, 2).npu()z = x.mm(y)print(z)
# 如果环境可用,这段代码输出如下:# tensor([[-0.9307, 2.9402],# [-0.4377, -1.5141]], device='npu:0')
准备好安装环境后,可通过以下步骤编译安装bitsandbytes:
xxxxxxxxxx1. git clone -b multi-backend-refactor https://github.com/bitsandbytes-foundation/bitsandbytes.git
2. cd bitsandbytes/
3. cmake -DCOMPUTE_BACKEND=npu -S .
4. make
5. pip install -e . # 安装前请确保进入了相应的Python环境,-e 表示“可编辑”安装,如果不是开发bnb,请去掉该选项如果在编译过程中出现异常,请在bitsandbytes目录下运行git clean -dfx清除所有编译产生的中间文件,然后检查编译环境,确认无误后重新运行上述3~5命令。
步骤2 启动QLoRA微调,在微调配置文件中,加入如下内容:
xxxxxxxxxxload_in_4bit: Truefinetuning_type: lorabf16: True需要注意的是,开启load_in_4bit: True时需要同时开启finetuning_type: lora和bf16: True。
微调参数说明
| 参数名 | 描述 | 类型 | 默认值 | 是否可选 |
|---|---|---|---|---|
| stage | 训练阶段,目前仅支持sft。 | str | sft | 可选 |
| finetuning_type | 微调方式。可选: full, lora。 | str | full | 可选 |
| lora_target_modules | 采取LoRA方法的目标模块。 | str | None | 可选 |
| lora_alpha | Lora微调的缩放因子。 | int | None | 可选 |
| lora_dropout | LoRA微调的丢弃率,取值范围为[0, 1)。 | float | 0.0 | 可选 |
| lora_rank | Lora微调的秩。 | int | 8 | 可选 |
| load_in_4bit | 支持QLoRA微调时使用4bit精度。 | bool | False | 可选 |
MindSpore模型微调
mindformers库是MindSpore模型开发的主流套件,为了方便用户进行模型微调,openMind Library对Auto Classes、Trainer和TrainingArguments接口统一进行了封装。
openMind Library封装的Auto Classes接口如下表所示。其余的Auto Classes接口openmind Library保留原生使用方式,如需使用,用户可自行从mindformers库中导入。
由于本次实操我们不使用MindSpore框架,因此我们不对MindSpore作深入了解。
三、微调流程分步详解
万事俱备,下面按照顺序详细讲解如何使用Qwen2.5-7B-Instruct进行微调。我们将结合OpenMIND Library框架生态工具,实现一个LoRA微调的示例。
3.1 选择并加载预训练模型
选择模型: 首先当然是选择合适的预训练模型作为微调基底。这里我们选用 Qwen2.5-7B-Instruct。这是阿里云通义千问团队开源的指令对齐大模型,拥有7B+参数并经过指令微调,擅长多语言对话、问答等任务。相较于未指令调优的基础模型,使用Qwen2.5-7B-Instruct可以大大缩短我们微调所需的收敛时间,并获得更好的指令执行效果。
基于此我们来构建yaml微调文件,加载模型:
xxxxxxxxxx# model
model_idQwen2.5-7B3.2 准备任务数据集
数据获取: 根据所选任务,获取相应的数据集。初学者可以选择公开的标注数据集:例如文本分类可使用中文情感分类数据集ChnSentiCorp或新闻主题分类(TNews),问答可以使用CMRC2018机器阅读理解数据,摘要任务可尝试LCSTS中文短文本摘要数据集,对话则有Belle开放对话数据或ShareGPT整理的对话数据等。许多数据集可以在Hugging Face Datasets或者国内的千言平台(LUGE)下载、魔乐社区下载。我们选择Alpaca数据集进行微调,Alpaca是是一个基于斯坦福大学发布的 Alpaca 数据集(52K 条英文指令跟随数据)翻译而来的中文指令微调数据集,旨在支持中文大语言模型(LLM)的训练与研究。
中文化处理:通过人工翻译和润色,确保指令和响应的语义准确性和自然流畅性。
数据格式:每条数据包含三个字段:
instruction:模型应执行的任务指令。input:任务的可选上下文或输入。output:模型应生成的响应。
数据量:约 77,500 条中文指令数据。

如果非已经处理好的数据,则我们需要数据清洗与格式转换 ,拿到数据后,需要进行清洗和格式标准化。去除明显的错误或噪声数据,以保证微调质量。接着,将数据转换为上一节定义的JSON格式或者其他适合的结构。对于Hugging Face的Datasets库,可以将数据处理成一个包含instruction, input, output字段的列表/表格,然后通过datasets.Dataset.from_pandas或load_dataset接口载入。在转换时,要特别注意确保指令提示和标签正确对应。例如分类任务中,不要把文本内容漏到instruction里,QA任务中问题和背景要清晰区分。下面给出将一个示例转换为我们所需格式的伪代码:
xxxxxxxxxximport json
# 假设我们有原始数据列表 raw_data,每项包含 text 和 labelfinetune_data = []for item in raw_data: finetune_data.append({ "instruction": "请判断以下文本的情感极性(正面或负面):", "input": item["text"], "output": "正面" if item["label"] == 1 else "负面" })# 将finetune_data保存为JSONL文件,每行一个JSONwith open("train_data.jsonl", "w", encoding="utf-8") as f: for entry in finetune_data: f.write(json.dumps(entry, ensure_ascii=False) + "\n")
准备好的JSONL文件可以直接被OpenMIND或Transformers的Trainer使用。在实际项目中,可能需要针对不同任务编写定制的处理脚本,但核心思想都是将数据整理为指令->输出的映射。
划分训练/验证集: 将清洗好的数据划分出一部分作为验证集(例如10%)。验证集不参与训练,用于在训练过程中评估模型性能,帮助我们判断何时停止训练以及是否过拟合等。如果有独立的测试集(用于最终评估),在微调过程中不要混用测试集,以免评估结果失真。
xxxxxxxxxx# dataset
datasetalpaca_zh_51kcutoff_len10243.3 微调模型
终于进入微调的核心步骤!我们将演示如何使用OpenMIND Library结合Transformers和LoRA来训练模型。
xxxxxxxxxx# method
stagesftdo_traintruefinetuning_typeloralora_alpha16lora_dropout0lora_rank8lora_target_modulesq_projstage: sft表示当前微调的阶段是 SFT(Supervised Fine-Tuning,有监督微调),也是最常见的微调第一阶段。
do_train: true启用训练流程。如果设为 false,系统只会进行模型加载或测试。
finetuning_type: lora表示使用 LoRA(低秩适配) 方法进行微调。相比全参数微调,LoRA 只训练部分参数,资源需求更低,非常适合在消费级显卡或小型服务器上训练。
lora_alpha: 16-LoRA 中的缩放因子,控制 LoRA 权重的影响程度。常见设置为 16、32 或 64。越大模型越容易拟合训练数据,过小可能学习不充分。
lora_dropout: 0-表示在注入的 LoRA 模块中是否使用 dropout 进行正则化,0 表示不启用,训练会更“稳定但可能过拟合”。如果数据量小,可以考虑加一点如 0.05~0.1。
lora_rank: 8-LoRA 的秩 r 值,决定引入的可训练参数规模,值越大模型拟合能力越强,但也更耗资源。常用值为 4、8、16,设为 8 是一个中等强度配置。
lora_target_modules: q_proj-指定要插入 LoRA 的模块名称。这里指定了 q_proj,表示只对 Attention 的 Query 投影层做插入。
你也可以改为
all,让 OpenMIND 自动选择多个目标模块(比如 q_proj, v_proj, o_proj, gate_proj 等)。如果你了解 Qwen 模型的结构,也可以精细控制,例如加上
"q_proj,v_proj"来增强效果。
3.4 模型输出与缓存配置
xxxxxxxxxxlogging_steps10save_steps20000overwrite_output_dirtruecache_dir/home/openmind/cache_modellogging_steps: 10
每训练多少步打印一次日志。设置为 1 表示每步都记录日志,有助于调试,但日志太频繁可能影响性能。
实际训练中建议设置为 10 或 50 更合理。
save_steps: 20000
每训练 20,000 步保存一次模型。如果训练步数没那么多,也可能只保存一次。
可以根据数据量和 batch size 调整。如果训练很短,建议缩小为如
1000。
overwrite_output_dir: true
如果输出目录存在,是否覆盖。
true表示会覆盖原有训练文件,小心误删旧模型。
cache_dir: /home/openmind/cache_model
设置模型缓存路径,避免每次重新从远程下载 Hugging Face 或 ModelScope 上的模型。
3.5训练输出路径设置
xxxxxxxxxxoutput_dirsaves/Qwen2-7B/sft/lora/overwrite_output_dirtrue微调后的模型(包括 LoRA adapter 权重、配置文件、训练日志等)将保存在这个目录中。
后续你可以使用:
openmind-cli chat --model saves/Qwen2-7B/sft/lora/来调用微调后模型。或者用
transformers + peft加载这个路径下的 LoRA 权重继续推理/评估。
总yaml文件:
xxxxxxxxxx# model
model_idQwen2.5-7B
# method
stagesftdo_traintruefinetuning_typeloralora_alpha16lora_dropout0lora_rank8lora_target_modulesq_proj
# dataset
datasetalpaca_zh_51kcutoff_len1024
# output
logging_steps1save_steps20000overwrite_output_dirtruecache_dir/home/openmind/cache_model
# train
output_dirsaves/Qwen2-7B/sft/lora/overwrite_output_dirtrue在我们已经创建的jupyter notebook中输入指令:
xxxxxxxxxxopenmind-cli train fine_tuning.yaml模型开始微调:

微调完毕之后我们可以在生成的输出目录下面看到微调过程生成的文件:

| 文件名 | 说明 |
|---|---|
checkpoint-19194/(或类似名) | 训练中保存的中间检查点,包含该步数时的模型权重、优化器状态等。用于中断恢复训练或模型回溯。 |
trainer_state.json | 记录整个训练过程的状态信息,例如当前epoch、step、loss曲线、最佳模型信息等。用于Trainer恢复训练或分析日志。 |
all_results.json | 汇总了训练过程中评估指标(如loss、accuracy等)的统计结果。适合用于实验对比分析。 |
train_results.json | 训练集上的性能指标。与all_results.json一起,用于衡量模型表现。 |
training_args.bin | 保存了训练参数对象(TrainingArguments)的二进制序列化结果,供后续载入模型时保持一致性。 |
added_tokens.json | 若你在分词器中添加了新的特殊Token(如<SYS>, <BOT>等),此处会记录新增的token信息。 |
merges.txt | BPE分词算法的merge规则文件,用于tokenizer解码。 |
tokenizer.json | 保存完整的Tokenizer结构,包括分词规则、vocab映射等。加载tokenizer时主要读取这个文件。 |
tokenizer_config.json | Tokenizer的配置信息,例如是否小写、添加哪些特殊Token、是否使用FastTokenizer等。 |
special_tokens_map.json | 标明特殊Token(如 [PAD], [CLS], [EOS] 等)在词表中的映射关系。 |
vocab.json | 词表文件(字典结构),用于将文本映射为token ID。 |
README.md | 微调后模型的说明文件,记录了训练信息、模型结构、使用方法等。部分由OpenMIND或Hugging Face生成。 |
adapter_config.json | LoRA 微调参数的配置信息(如rank、alpha、target_modules等),供加载LoRA权重时使用。 |
adapter_model.safetensors | 核心LoRA微调权重文件,保存了训练后的LoRA adapter 参数。可用于部署或加载微调结果。使用safetensors格式比.bin更安全高效。 |
那么我们怎么使用这些文件,用这些文件做什么呢?
3.5.1继续训练
可以通过 checkpoint-19194 目录恢复训练:
xxxxxxxxxxopenmind-cli train your_config.yaml --resume_from_checkpoint checkpoint-191943.5.2. 加载 LoRA 微调模型进行推理
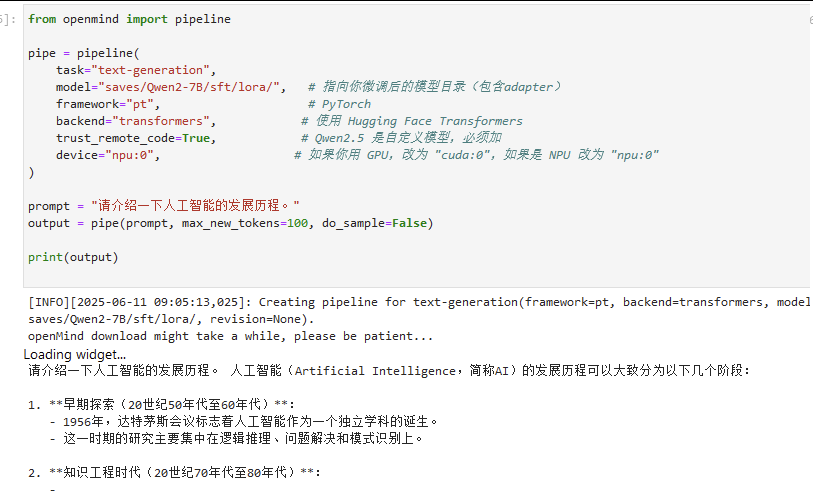
xxxxxxxxxxfrom openmind import pipeline
pipe = pipeline( task="text-generation", model="saves/Qwen2-7B/sft/lora/", # 指向你微调后的模型目录(包含adapter) framework="pt", # PyTorch backend="transformers", # 使用 Hugging Face Transformers trust_remote_code=True, # Qwen2.5 是自定义模型,必须加 device="npu:0", # 如果你用 GPU,改为 "cuda:0",如果是 NPU 改为 "npu:0")
prompt = "请介绍一下人工智能的发展历程。"output = pipe(prompt, max_new_tokens=100, do_sample=False)
print(output)
3.6模型评估与效果解读
微调后的模型需要通过评估来验证它在目标任务上的表现是否达标。评估可以在验证集或独立的测试集上进行。常见的评价指标因任务类型不同而有所差异:
文本分类任务指标: 使用准确率(Accuracy)*和*F1分数来衡量分类模型性能。准确率是指模型预测正确的比例,直观反映总体正确率。而F1分数是精确率和召回率的调和平均,特别适用于类别不平衡时评估模型综合能力。例如,在情感分类中,Accuracy直接看正负面判断的总体正确率;而F1则考虑了模型对正负两类是否均衡掌握。一般还会给出精确率(Precision)和召回率(Recall)以帮助理解模型是偏保守(Precision高Recall低)还是偏激进(Recall高Precision低)。
问答任务指标: 视问答类型而定。如果是抽取式问答(答案直接从给定文本中抽取),常用准确匹配率(Exact Match)*和*F1作为指标,计算模型输出与标准答案在字词上的重叠程度。如果是开放问答/生成式问答,则可以采用BLEU或ROUGE-L等度量生成答案和参考答案的相似度。Accuracy有时也用于选择题或知识问答看模型答对多少道。对于多轮对话类的问答,还可以有人为评分来评估答案的有用性和正确性。
摘要和翻译等生成任务指标: ROUGE和BLEU是评估文本生成质量的两大经典自动指标。ROUGE(Recall-Oriented Understudy for Gisting Evaluation)偏重召回率,衡量模型生成的摘要覆盖了多少参考摘要中的重要内容。常用ROUGE-N(如ROUGE-1,2计算1元词和2元词的召回)、ROUGE-L(Longest Common Subsequence衡量最长公共子序列)等。BLEU(Bilingual Evaluation Understudy)最初用于机器翻译评估,它通过计算模型输出和参考文本之间的n元组重叠率来判断相似度,更强调生成文本与参考文本在字词上的精确匹配程度。简单来说,ROUGE看生成是否涵盖了参考答案的大部分内容,BLEU看生成是否在措辞上与参考答案一致。摘要任务通常报告ROUGE-1/2/L分数,翻译任务多用BLEU。
对话生成任务指标: 对话系统的评价较为困难,常用的自动指标包括BLEU(计算模型回复与参考回复的n元重合)和ROUGE,但它们未必能充分反映对话的质量和连贯性。还有一些专门评估对话的指标如对话篇章一致性、知识准确性等等。实践中,对话生成更多还是依赖人工评价(比如让人类评委打分模型回复的有用性、流畅度等)。不过在开发阶段,可以通过困惑度(Perplexity)来衡量模型对话生成的流畅性——在验证集上计算语言模型困惑度以粗略评估模型是否过拟合。综上,对话生成任务可以结合自动指标和人审,综合判断模型效果。
结果解读: 一旦得到指标,需要结合任务性质进行解读。分类任务的Accuracy直观易懂,但对于类别不平衡的数据,更关注F1是否足够高。问答任务,如果F1仍较低,可能是模型答案不完整或语言表达不同(哪怕意思相同)。摘要任务的ROUGE分数一般不可能100%,能到达30-50已经是较不错的效果——因为摘要允许多种表达,模型未必字字匹配参考摘要。对话任务如果用BLEU等指标,分数通常更低,因为开放式对话的合理回应千差万别,自动指标无法全面评价。
因此,我们在看指标时,应纵向比较模型自身在相同数据集上的提升,而不宜简单横向和其他任务比较。例如,分类可以期望90%以上准确率,而开放问答的BLEU可能只有20但已经表示模型学会了一些回答技巧。最后,别忘了人工测试模型:直接与模型对话、让模型生成摘要,看主观上是否符合预期。这有助于发现自动指标未能反映的问题。
微调流程小结: 按照以上步骤,我们完成了从选模型、备数据、配参数,到启动训练、监控收敛,再到模型评估的全过程。对于初学者来说,每一步都需要细心和反复试验。遇到问题时,多查看日志和错误信息,必要时减少任务难度(比如先在小数据集上跑一个epoch看看输出是否正常)。通过这次实战,读者应当对大语言模型微调有了初步认识:大模型微调并不神秘,它是有章可循的工程流程。
最后,鼓励大家多多尝试不同的任务和数据,用Qwen2.5-7B-Instruct这样的开源大模型进行创造性的实验。在实践中积累经验,熟悉各类坑和解决方案,你也可以驾驭大语言模型去完成各种有趣的应用!祝你在大模型微调之旅上收获满满。